
[ Go Back ]
This guide provides an overview of High Availability of YARN's ResourceManager, and details how to configure and use this feature. The ResourceManager (RM) is responsible for tracking the resources in a cluster, and scheduling applications (e.g., MapReduce jobs). Prior to Hadoop 2.4, the ResourceManager is the single point of failure in a YARN cluster. The High Availability feature adds redundancy in the form of an Active/Standby ResourceManager pair to remove this otherwise single point of failure.
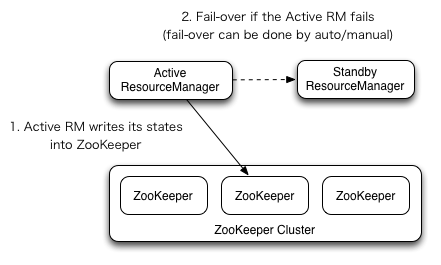
ResourceManager HA is realized through an Active/Standby architecture - at any point of time, one of the RMs is Active, and one or more RMs are in Standby mode waiting to take over should anything happen to the Active. The trigger to transition-to-active comes from either the admin (through CLI) or through the integrated failover-controller when automatic-failover is enabled.
When automatic failover is not enabled, admins have to manually transition one of the RMs to Active. To failover from one RM to the other, they are expected to first transition the Active-RM to Standby and transition a Standby-RM to Active. All this can be done using the "yarn rmadmin" CLI.
The RMs have an option to embed the Zookeeper-based ActiveStandbyElector to decide which RM should be the Active. When the Active goes down or becomes unresponsive, another RM is automatically elected to be the Active which then takes over. Note that, there is no need to run a separate ZKFC daemon as is the case for HDFS because ActiveStandbyElector embedded in RMs acts as a failure detector and a leader elector instead of a separate ZKFC deamon.
When there are multiple RMs, the configuration (yarn-site.xml) used by clients and nodes is expected to list all the RMs. Clients, ApplicationMasters (AMs) and NodeManagers (NMs) try connecting to the RMs in a round-robin fashion until they hit the Active RM. If the Active goes down, they resume the round-robin polling until they hit the "new" Active. This default retry logic is implemented as org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider. You can override the logic by implementing org.apache.hadoop.yarn.client.RMFailoverProxyProvider and setting the value of yarn.client.failover-proxy-provider to the class name.
With the ResourceManger Restart enabled, the RM being promoted to an active state loads the RM internal state and continues to operate from where the previous active left off as much as possible depending on the RM restart feature. A new attempt is spawned for each managed application previously submitted to the RM. Applications can checkpoint periodically to avoid losing any work. The state-store must be visible from the both of Active/Standby RMs. Currently, there are two RMStateStore implementations for persistence - FileSystemRMStateStore and ZKRMStateStore. The ZKRMStateStore implicitly allows write access to a single RM at any point in time, and hence is the recommended store to use in an HA cluster. When using the ZKRMStateStore, there is no need for a separate fencing mechanism to address a potential split-brain situation where multiple RMs can potentially assume the Active role.
Most of the failover functionality is tunable using various configuration properties. Following is a list of required/important ones. yarn-default.xml carries a full-list of knobs. See yarn-default.xml for more information including default values. See the document for ResourceManger Restart also for instructions on setting up the state-store.
| Configuration Property | Description |
|---|---|
| yarn.resourcemanager.zk-address | Address of the ZK-quorum. Used both for the state-store and embedded leader-election. |
| yarn.resourcemanager.ha.enabled | Enable RM HA |
| yarn.resourcemanager.ha.rm-ids | List of logical IDs for the RMs. e.g., "rm1,rm2" |
| yarn.resourcemanager.hostname.rm-id | For each rm-id, specify the hostname the RM corresponds to. Alternately, one could set each of the RM's service addresses. |
| yarn.resourcemanager.ha.id | Identifies the RM in the ensemble. This is optional; however, if set, admins have to ensure that all the RMs have their own IDs in the config |
| yarn.resourcemanager.ha.automatic-failover.enabled | Enable automatic failover; By default, it is enabled only when HA is enabled. |
| yarn.resourcemanager.ha.automatic-failover.embedded | Use embedded leader-elector to pick the Active RM, when automatic failover is enabled. By default, it is enabled only when HA is enabled. |
| yarn.resourcemanager.cluster-id | Identifies the cluster. Used by the elector to ensure an RM doesn't take over as Active for another cluster. |
| yarn.client.failover-proxy-provider | The class to be used by Clients, AMs and NMs to failover to the Active RM. |
| yarn.client.failover-max-attempts | The max number of times FailoverProxyProvider should attempt failover. |
| yarn.client.failover-sleep-base-ms | The sleep base (in milliseconds) to be used for calculating the exponential delay between failovers. |
| yarn.client.failover-sleep-max-ms | The maximum sleep time (in milliseconds) between failovers |
| yarn.client.failover-retries | The number of retries per attempt to connect to a ResourceManager. |
| yarn.client.failover-retries-on-socket-timeouts | The number of retries per attempt to connect to a ResourceManager on socket timeouts. |
Here is the sample of minimal setup for RM failover.
<property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.cluster-id</name> <value>cluster1</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>master1</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>master2</value> </property> <property> <name>yarn.resourcemanager.zk-address</name> <value>zk1:2181,zk2:2181,zk3:2181</value> </property>
yarn rmadmin has a few HA-specific command options to check the health/state of an RM, and transition to Active/Standby. Commands for HA take service id of RM set by yarn.resourcemanager.ha.rm-ids as argument.
$ yarn rmadmin -getServiceState rm1 active $ yarn rmadmin -getServiceState rm2 standby
If automatic failover is enabled, you can not use manual transition command.
$ yarn rmadmin -transitionToStandby rm1 Automatic failover is enabled for org.apache.hadoop.yarn.client.RMHAServiceTarget@1d8299fd Refusing to manually manage HA state, since it may cause a split-brain scenario or other incorrect state. If you are very sure you know what you are doing, please specify the forcemanual flag.
See YarnCommands for more details.
Assuming a standby RM is up and running, the Standby automatically redirects all web requests to the Active, except for the "About" page.
Assuming a standby RM is up and running, RM web-services described at ResourceManager REST APIs when invoked on a standby RM are automatically redirected to the Active RM.