
This guide provides an overview of the HDFS Federation feature and how to configure and manage the federated cluster.
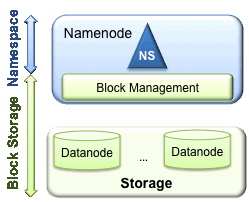
HDFS has two main layers:
The prior HDFS architecture allows only a single namespace for the entire cluster. A single Namenode manages this namespace. HDFS Federation addresses limitation of the prior architecture by adding support multiple Namenodes/namespaces to HDFS file system.
In order to scale the name service horizontally, federation uses multiple independent Namenodes/namespaces. The Namenodes are federated, that is, the Namenodes are independent and don’t require coordination with each other. The datanodes are used as common storage for blocks by all the Namenodes. Each datanode registers with all the Namenodes in the cluster. Datanodes send periodic heartbeats and block reports and handles commands from the Namenodes.
Users may use ViewFs to create personalized namespace views, where ViewFs is analogous to client side mount tables in some Unix/Linux systems.
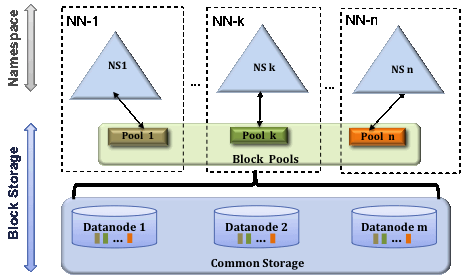
Block Pool
A Block Pool is a set of blocks that belong to a single namespace. Datanodes store blocks for all the block pools in the cluster. It is managed independently of other block pools. This allows a namespace to generate Block IDs for new blocks without the need for coordination with the other namespaces. The failure of a Namenode does not prevent the datanode from serving other Namenodes in the cluster.
A Namespace and its block pool together are called Namespace Volume. It is a self-contained unit of management. When a Namenode/namespace is deleted, the corresponding block pool at the datanodes is deleted. Each namespace volume is upgraded as a unit, during cluster upgrade.
ClusterID
A new identifier ClusterID is added to identify all the nodes in the cluster. When a Namenode is formatted, this identifier is provided or auto generated. This ID should be used for formatting the other Namenodes into the cluster.
Federation configuration is backward compatible and allows existing single Namenode configuration to work without any change. The new configuration is designed such that all the nodes in the cluster have same configuration without the need for deploying different configuration based on the type of the node in the cluster.
A new abstraction called NameServiceID is added with federation. The Namenode and its corresponding secondary/backup/checkpointer nodes belong to this. To support single configuration file, the Namenode and secondary/backup/checkpointer configuration parameters are suffixed with NameServiceID and are added to the same configuration file.
Step 1: Add the following parameters to your configuration: dfs.nameservices: Configure with list of comma separated NameServiceIDs. This will be used by Datanodes to determine all the Namenodes in the cluster.
Step 2: For each Namenode and Secondary Namenode/BackupNode/Checkpointer add the following configuration suffixed with the corresponding NameServiceID into the common configuration file.
| Daemon | Configuration Parameter |
|---|---|
| Namenode | dfs.namenode.rpc-address dfs.namenode.servicerpc-address dfs.namenode.http-address dfs.namenode.https-address dfs.namenode.keytab.file dfs.namenode.name.dir dfs.namenode.edits.dir dfs.namenode.checkpoint.dir dfs.namenode.checkpoint.edits.dir |
| Secondary Namenode | dfs.namenode.secondary.http-address dfs.secondary.namenode.keytab.file |
| BackupNode | dfs.namenode.backup.address dfs.secondary.namenode.keytab.file |
Here is an example configuration with two namenodes:
<configuration>
<property>
<name>dfs.nameservices</name>
<value>ns1,ns2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1</name>
<value>nn-host1:rpc-port</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1</name>
<value>nn-host1:http-port</value>
</property>
<property>
<name>dfs.namenode.secondaryhttp-address.ns1</name>
<value>snn-host1:http-port</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns2</name>
<value>nn-host2:rpc-port</value>
</property>
<property>
<name>dfs.namenode.http-address.ns2</name>
<value>nn-host2:http-port</value>
</property>
<property>
<name>dfs.namenode.secondaryhttp-address.ns2</name>
<value>snn-host2:http-port</value>
</property>
.... Other common configuration ...
</configuration>Step 1: Format a namenode using the following command:
> $HADOOP_PREFIX_HOME/bin/hdfs namenode -format [-clusterId <cluster_id>]
Choose a unique cluster_id, which will not conflict other clusters in your environment. If it is not provided, then a unique ClusterID is auto generated.
Step 2: Format additional namenode using the following command:
> $HADOOP_PREFIX_HOME/bin/hdfs namenode -format -clusterId <cluster_id>
Note that the cluster_id in step 2 must be same as that of the cluster_id in step 1. If they are different, the additional Namenodes will not be part of the federated cluster.
Older releases supported a single Namenode. Upgrade the cluster to newer release to enable federation During upgrade you can provide a ClusterID as follows:
> $HADOOP_PREFIX_HOME/bin/hdfs start namenode --config $HADOOP_CONF_DIR -upgrade -clusterId <cluster_ID>
If ClusterID is not provided, it is auto generated.
Follow the following steps:
> $HADOOP_PREFIX_HOME/bin/hdfs dfadmin -refreshNameNode <datanode_host_name>:<datanode_rpc_port>
To start the cluster run the following command:
> $HADOOP_PREFIX_HOME/bin/start-dfs.sh
To stop the cluster run the following command:
> $HADOOP_PREFIX_HOME/bin/stop-dfs.sh
These commands can be run from any node where the HDFS configuration is available. The command uses configuration to determine the Namenodes in the cluster and starts the Namenode process on those nodes. The datanodes are started on nodes specified in the slaves file. The script can be used as reference for building your own scripts for starting and stopping the cluster.
Balancer has been changed to work with multiple Namenodes in the cluster to balance the cluster. Balancer can be run using the command:
"$HADOOP_PREFIX"/bin/hadoop-daemon.sh --config $HADOOP_CONF_DIR --script "$bin"/hdfs start balancer [-policy <policy>]
Policy could be:
Note that Balander only balances the data and does not balance the namespace.
Decommissioning is similar to prior releases. The nodes that need to be decomissioned are added to the exclude file at all the Namenode. Each Namenode decommissions its Block Pool. When all the Namenodes finish decommissioning a datanode, the datanode is considered to be decommissioned.
Step 1: To distributed an exclude file to all the Namenodes, use the following command:
"$HADOOP_PREFIX"/bin/distributed-exclude.sh <exclude_file>
Step 2: Refresh all the Namenodes to pick up the new exclude file.
"$HADOOP_PREFIX"/bin/refresh-namenodes.sh
The above command uses HDFS configuration to determine the Namenodes configured in the cluster and refreshes all the Namenodes to pick up the new exclude file.
Similar to Namenode status web page, a Cluster Web Console is added in federation to monitor the federated cluster at http://<any_nn_host:port>/dfsclusterhealth.jsp. Any Namenode in the cluster can be used to access this web page.
The web page provides the following information: